如何进入大模型领域
22 年底 Stable Diffusion 和 ChatGPT 的公开面世,彻底引爆了这一波 AI 浪潮,AI 在很多方面实际改变了我们的生活。作为工程师,如何进入大模型领域,追踪趋势,把这一波生成式人工智能的前沿成果应用到我们的实际工作中呢?下面是我个人总结的路径。
在 X 追踪 influencers
追踪大模型领域最新进展最佳办法是在 follow X 上 AI 领域活跃的人,我发现这一波风口的人比较喜欢在 X 上发表言论。在 X 上我觉得要关注两类人:
- 优质信息的转发者,比如 AI&Tech 中文优质推主
- 真正对 AI 有 insight 的人,比如 AI Leaders
关于追踪的小技巧:
- 如果你发现一个推主内容不错,可以点击去看 ta 都关注了哪些人,顺藤摸瓜关注一圈
- 人的精力是有限的,对自己的信息源进行筛选
避免 FOMO
FOMO 是 "Fear of Missing Out" 的缩写,意为"错失恐惧症"。这是一种社会焦虑的表现,具体指担心错过令人兴奋或有趣的事情,担心自己没跟上朋友的生活节奏。在互联网和社交媒体时代,FOMO 变得更加普遍。
在去年的某个时间段,由于 AI 成果和产品,很容易让人有 FOMO 情绪。有这情绪非常正常,但不要沉溺在情绪中,最佳的办法是动手实践。
阅读 Paper
阅读 Paper 是积累专业知识的最佳办法,学者都会通过发表 Paper 展示最新的研究成果。我把 Paper 当做某种特殊格式的博客来阅读。
Paper 的信息源
- 如果你想要了解一个领域,可以先从论文综述开始
- 比如你想了解 AI Agents 领域,可以综述文章开始 LLM Powered Autonomous Agents | Lil’Log 按图索骥
- 一些 AI 工具也有一些必读论文 AI-Agents必读论文 - 必读论文 - AMiner
- 如果你想要追逐热点:Trending Papers
- 一些个人推荐:比如 hugging face 的 ak 每日都会推荐论文 Daily Papers - Hugging Face
如何读 Paper
第一步:用15分钟快速浏览论文,重点是对研究内容有一个整体的高层次理解。 第二步:花一个小时深入分析论文的设计、实施和评估细节。 第三步:用自己的语言总结论文内容,以便更好地内化和理解这些研究成果。
在此基础上,我一般会加上:
- 第零步:使用 AI 帮我总结,我会把 pdf 丢给大模型,通过类似“帮我总结这篇论文,并提出 3 个问题并自己回答”的 Prompt
- 第四步:去 GitHub 或者 The latest in Machine Learning | Papers With Code 看看这篇论文有没有配套的代码
观看视频
有时 Paper 读累了,或者论文很不好理解,可以选择看视频。目前有很多优质 Up 主制作的视频,比如
夯实基础 如果在学习路径上,如果遇到不明白的概念,可以先问 GPT,目前 GPT 就是最好的老师。 如果真的对深度学习领域感兴趣,想系统学习一下,可以看看 Coursera 的课程和相关推荐书籍。这方面互联网课程实在太多了,比如 纯新手自学入门机器/深度学习指南(附一个月速成方案)。
开源模型 vs 闭源模型
Strong opinions, weakly held.
最近李彦宏的一句“开源模型会越来越落后”在互联网引发了一些讨论。
诸如 Windows和Linux、IE 和 Mozilla、iOS 和 Android 开源和闭源的战争,在计算机和软件行业已经持续很长一段时间。LLM 横空出世后,基础大模型的格局,到底是寡头垄断还是开源满天下?
屁股决定脑袋
Kimi 的创始人有一段访谈: 对话月之暗面杨植麟:向延绵而未知的雪山前进。
「因为开源的开发方式跟以前不一样了,以前是所有人都可以 contribute(贡献)到开源,现在开源本身还是中心化的。开源的贡献可能很多都没有经过算力验证。闭源会有人才聚集和资本聚集,最后一定是闭源更好,是一个consolidation(对市场的整合)。 如果我今天有一个领先的模型,开源出来,大概率不合理。反而是落后者可能会这么做,或者开源小模型,搅局嘛,反正不开源也没价值。」
开源其实是商业中很经典的策略 Reverse Positioning 逆向定位 - MBA智库百科。
Linux 在 90 年代得到 IBM 大力资助,以抗衡微软;Google用Android的开放生态与苹果竞争。
如今“一点都不 Open” 的 OpenAI 坚持闭源,Meta 却积极拥抱开源,背后主要还是生意上的考量。
枷锁是成本
过往的 AI 前沿成果更多出现在学术界,但大语言模型极高的训练成本的改变这一现状。现在实际情况是高校很难一次性给出数千万美元的研究经费,真实情况是实验室能有几十块 A100 就算是顶配了。
回顾 OpenAI 发展历程中最关键的决策,正是和微软深度绑定,因为创始人意识到大模型这件事,作为非营利组织是搞不定的,算力、数据和钱都远远不够,所以他们接受了微软 10 亿美金投资。
开源永远存在
虽然我个人不看好基础大模型的开源之路,但有两点开源模型非常有优势,一个是私有化部署的需求,一个是开发者生态。
私有化部署 大模型服务绝对绕不开的话题之一就是数据安全。尽管 OpenAI 早在去年就推出了隐私数据和个人安全的声明,还加上 Enterprise 版本,承诺不拿企业客户的数据做 Training。但只要数据上传,猜疑链就永远存在,比如公司 Ban 掉 Github Copilot。私有化部署开源模型,目前看仍是兼顾效果和安全的最佳方案。
开发者生态 一旦有性能仅略微落后于头部闭源模型的开源模型出现,社区的兴趣会全面转向基于开源模型的二次开发和 fine-tuning。 从历史上看,开源往往比闭源有更高的集中度,有更难撼动的生态壁垒。围绕开源模型的参与节点间会出现类似互联网产品的网络效应,这种效应如今在Hugging Face中已初见雏形。
通往 AGI 之路
目前看来我认为闭源有优势。 一些朴素的观察:
- 做大模型本身对工程要求很高:OpenAI 被曝光 19 年的时候就找 PhD 去做标注数据,也就意味着最顶尖的大模型公司掌握着独特的标注数据的方法,不是以往人工智能公司找外包去做这样的事情
- 经济成本:GPT 的 turbo 版本效果持平,成本减少 10 倍;商业竞争下,相比于后发者,先发的 OpenAI 同时具备成本优势;
- 时间成本:pretrain 的成本极大,训练的时间实在太长了,具备 know how 的公司可以大大缩短探索方向的时间;烧钱也很难解决;
- 飞轮效应:ChatGPT 上亿日活,积累无数的用户问题和反馈,这是开源模型无法比拟的优势,这样的优势会形成正反馈飞轮,强者愈强;
- 同行对比:谷歌作为世界最顶尖的科技公司之一,在算力、数据、人才密度上领先的情况下,花了整整一年的时间 Gemini 才勉强面世,目前个人体验下来还是很糟糕,距离 GPT4 还有很大差距;从谷歌的追赶程度看,侧面印证了大模型的难度很高;
大模型时代,我们应该做什么
时间回溯到 90 年代,当浏览器刚推出的时候,我们不应该再去从头做个浏览器,而是去做个网页。
时间回溯到 10 年代,当 iPhone 横空出世的时候,我们不应该去模仿 iPhone 做山寨机,而是去做 iOS 应用。
大模型爆发的黎明,我们应该做什么?
比尔盖茨给的答案是:Agent
The most exciting impact of AI agents is the way they will democratize services that today are too expensive for most people. They’ll have an especially big influence in four areas: health care, education, productivity, and entertainment and shopping.
Bill Gates: AI is about to completely change how you use computers
AI Agents 的最激动人心的影响之一是它将让当前对多数人而言价格不菲的服务变得触手可及。在医疗保健、教育、提升工作效率、娱乐与购物这四大领域,AI Agents 的作用尤为显著。
吴恩达给的答案是:AI agentic workflows
I think AI agentic workflows will drive massive AI progress this year — perhaps even more than the next generation of foundation models. This is an important trend, and I urge everyone who works in AI to pay attention to it.
我认为今年 AI 主体工作流程将推动 AI 取得巨大进展——甚至可能超过下一代基础模型。这是一个重要的趋势,我敦促所有从事 AI 工作的人都要关注它。
做正确的事儿比正确的做事儿更重要。
在科技领域,我们总是高估在一年或者两年中能够做到的,而低估五年或者十年中能够做到的。
目前大量的学者在研究 Agent 领域,公司在开发 Agent 产品,但截止到 2024.5,还没有令人眼前一亮的、改变游戏的 Agent 产品面世,大家还是在以做调研和做 demo 为主。我觉得主要原因是,现阶段模型能力还没有那么强,效果仍不尽人意。
这一波浪潮其实对工程师是福音。算法平权为我们带来最大的好处是,可以把原来很多需要比较深算法功底的功能快速落地。
如果对最新的 AI 应用和产品感兴趣,可以通过 最好的AI导航站和AI工具列表 - Toolify 去看。有创业想法的同学可以看看排行榜,通常热度高代表需求旺盛。
广告平台 Agent 需要哪些配套设施
回顾 Agent 的几个重要组件:
- Planning
- 子目标和分解:Agent 将大型任务分解为更小的、可管理的子目标,从而能够有效处理复杂的任务
- 反思和完善:Agent 可以对过去的行为进行自我批评和自我反思,从错误中吸取教训,并针对未来的步骤进行完善,从而提高最终结果的质量。
- Memory
- 短期记忆:所有的上下文学习都是利用模型的短期记忆来学习
- 这为 Agent 提供了长时间保留和回忆(无限)信息的能力,通常是通过利用外部向量存储和快速检索
- Tool
- Agent 学习调用外部 API 来获取模型权重中缺失的额外信息(通常在预训练后很难更改),包括当前信息、代码执行能力、对专有信息源的访问等。
我认为做好广告平台 Agent 这样的产品,有两点是我认为特别重要的:
- 工具的使用:如何把广告平台现有能力(API)让大模型便捷地使用,因为“调用外部 API 来获取模型权重中缺失的额外信息”这部分大模型再厉害,他也不知道即时&正确的信息
- 如何迭代我们的产品:让我们的产品形成正向飞轮
广告平台的 Microsoft Graph
Microsoft 365 Copilot 最核心的三个组件:
- Microsoft Application Suite
- Microsoft Graph:提供的核心能力是 Grounded in your business data
- Large Language Model 之间的协作关系是:
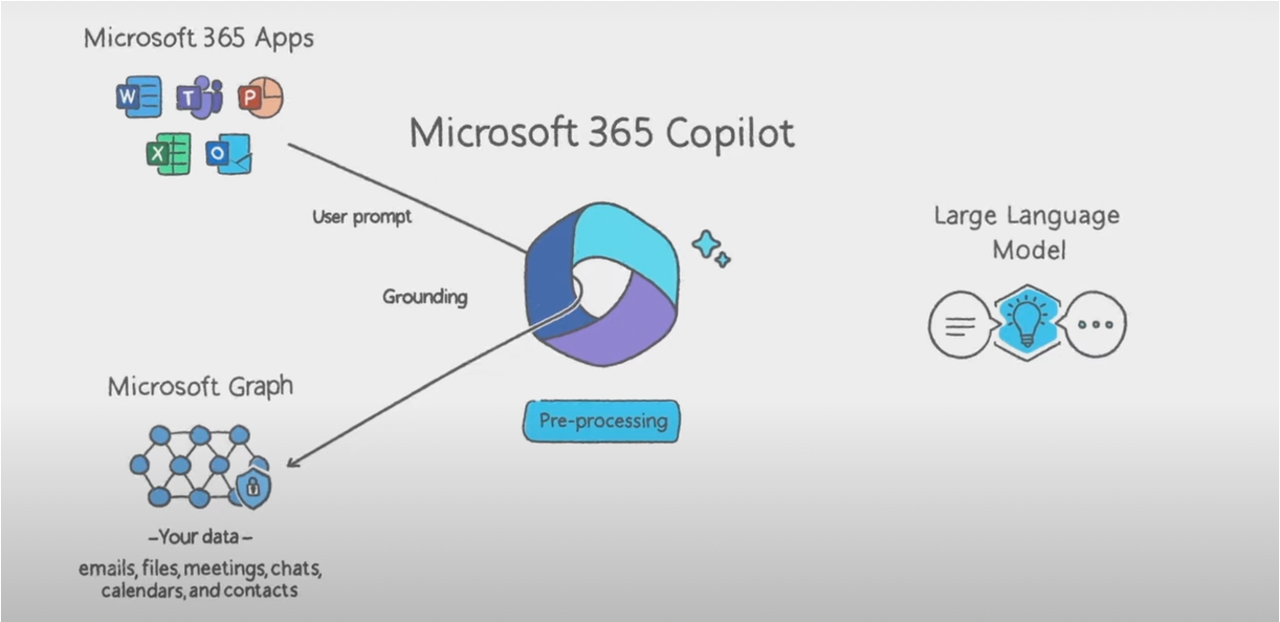
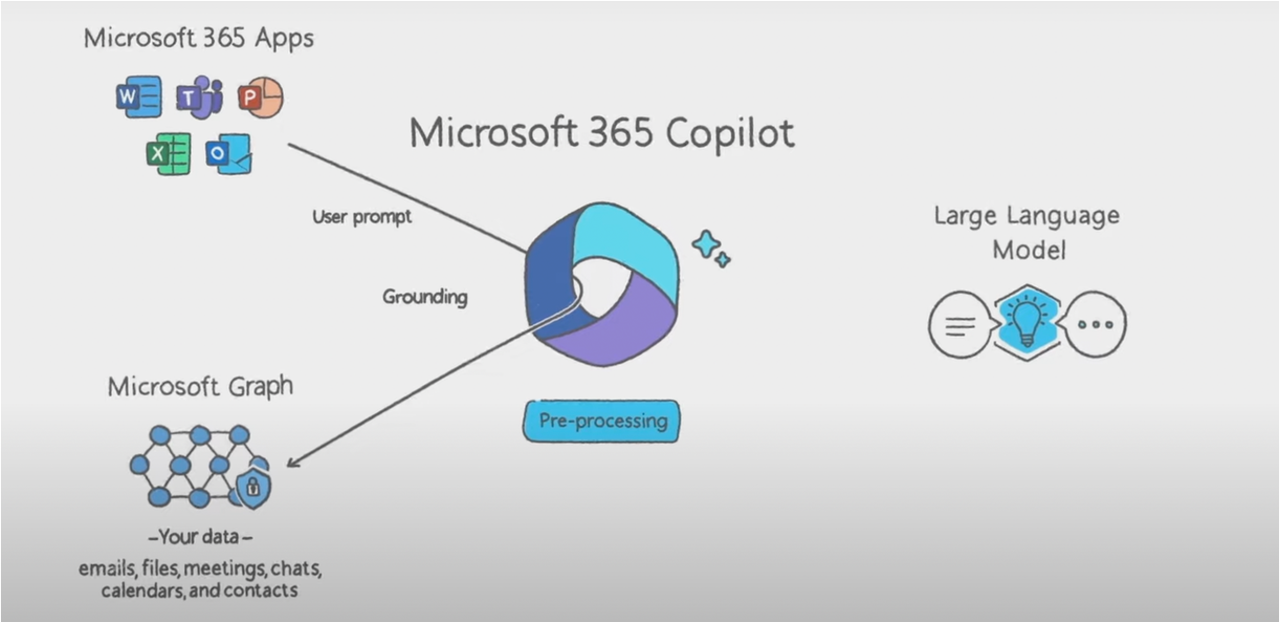
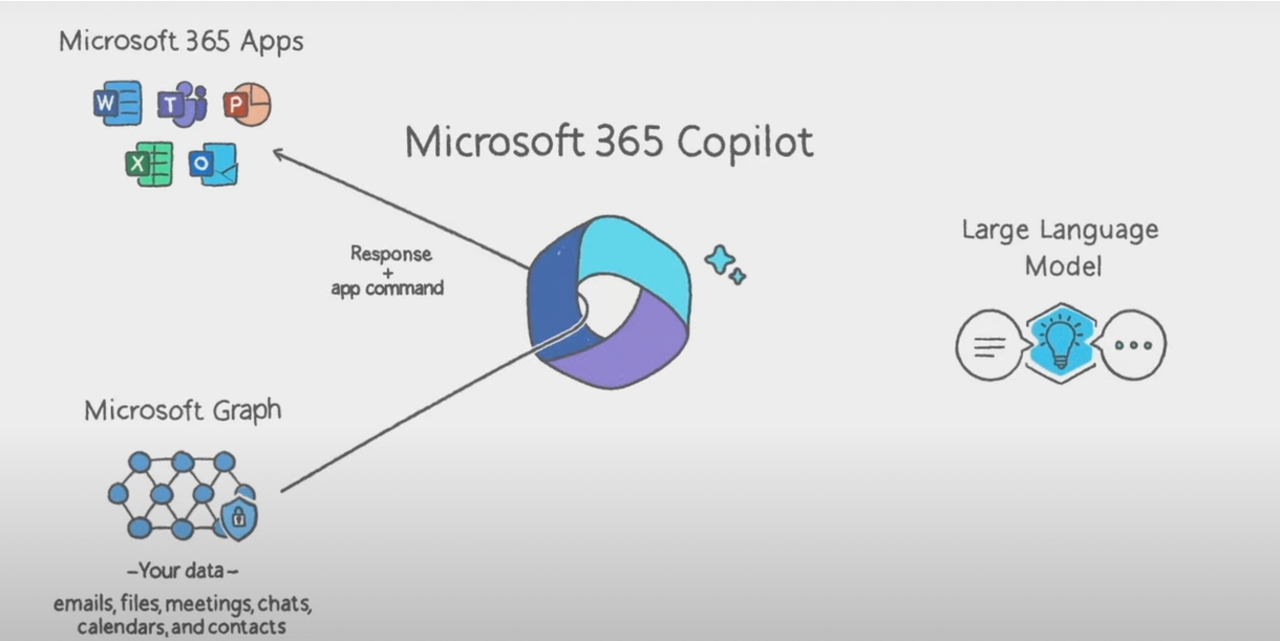
Microsoft 365 Copilot 受益于 Microsoft Graph 提供的统一网关能力,能够快速支持调度 Microsoft 365 各个产品线的 API。同理,广告平台 Copilot 也需要类似的网关基建来实现便捷的 Tool 调用能力。
广告平台的 LangSmith
产品上线以来,如何迭代优化大语言模型的能力一直是我们很关心的问题:
- 如何观测线上大语言模型任务的准确率,包括意图识别,数分插件的提槽准确率
- 在增加插件的时候,如何确保意图识别是准确和维持准确率水位的
在阅读 Github 微博 The architecture of today’s LLM applications - The GitHub Blog (推荐阅读,做大语言模型产品很多思路是类似的),文章提到在线评估的重要性。
Why are online evaluations important?
Although a model might pass an offline test with flying colors, its output quality could change when the app is in the hands of users. This is because it’s difficult to predict how end users will interact with the UI, so it’s hard to model their behavior in offline tests.
为什么在线评估很重要?
尽管模型可能在离线测试中表现出色,但其输出质量在应用程序落入用户手中时可能会有所变化。这是因为很难预测最终用户将如何与UI进行交互,因此很难在离线测试中对其行为建模。
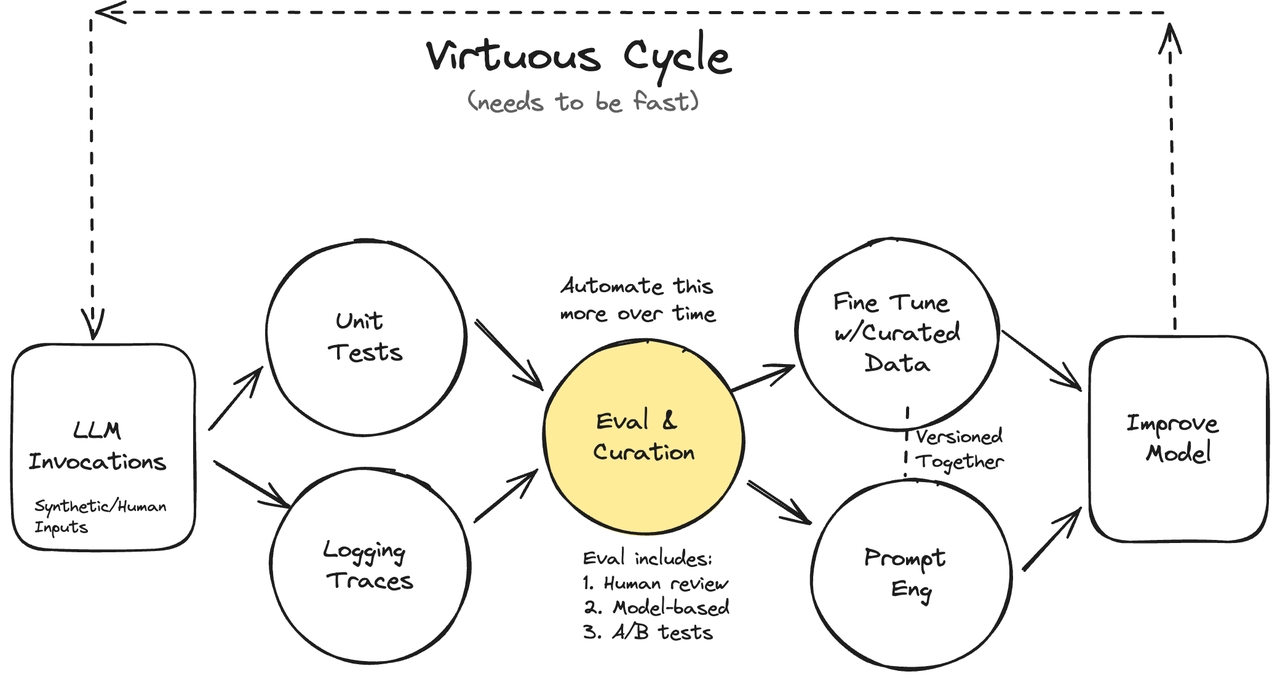
一个强大可靠的 Evaluation 系统对于大模型产品的成功是至关重要的。